※ 引述《jeff0025 (無法顯示人物名稱)》之銘言:
: OpenAI 指出,GPT-5.2 的設計目標是協助專業人士提升效率,從製作試算表、簡報、撰
: 寫程式碼,到解析影像、理解長文件、運用工具與執行多步驟任務。根據官方數據,一般
: 企業戶平均每天可節省 40~60 分鐘,重度用戶甚至可省下每周10 小時以上。
官網有貼出將近二十家企業端用戶早期測試組的評測
可見這次更新主要是為了專業用途
https://openai.com/zh-Hant/index/introducing-gpt-5-2/
Windsurf Warp JetBrains Augment Code Cline Charlie Labs Kilo Azad
Triple Whale Notion Zoom Box Hex Databriks Harvey Parloa
MoveWorks Shopify
上述評測企業分為三大群:
軟體開發與 AI 程式設計工具、企業協作與數據平台、AI 與自動化服務
企業用戶不會輕易跳槽
即使Gemini 3.0 pro或Claude Opus 4.5上市之後表現勝出
根據Ramp AI Index的統計 美國企業的AI模型採用普及率為45
https://i.imgur.com/8rAigBA.png
OPEN AI的企業採用率是34.8 Anthropic(Claude)的企業採用率是15.1
其他主要AI公司的採用率都是低於5 包括Google的Gemini在內
不過這是今年十月的統計 是在Gemini 3.0 pro上市之前
GPT5.2官網第一句話寫:為專業工作與長時間運行的代理而打造
如果那些企業善用這個長任務代理的功能 將會更難跳槽
另外值得關注的是 GPT5.2的ARC-AGI-2成績高達50幾
這個測驗是在測解決未知任務的推理能力(當然是模擬的)
https://i.imgur.com/N6V3Kkv.png
不過也可以看到Gemini 3.0 pro優化後的成績從30幾跳躍到50幾
人類一般受試者平均是66喔
我前陣子有上測驗官網做了大概六題 因為粗心錯一半 所以我大概只有50左右
這些模型的流體智力已經超過我啦QQ
提供參考 我的WAIS知覺推理成績是118 中等偏高
聽說非母語環境所以有受影響(因為腦袋要同時理解外語資訊)
好恐怖 今年四月OPEN AI的o3的成績才5~6左右耶 才過半年多 新模型就50幾了
等到100的時候不知道會變怎樣
: 已反應? 這次發布後好像沒啥人在意 AI真的要泡沫化了嗎?
: 感覺OpenAI一直強調多強好像對一般使用者來說根本無感
: Gemini有完整生態系 還送2TB雲端空間 又能一個人購買多人共享
: 然後生成圖片又強
一般使用者無感很正常 因為這次推出的GPT5.2是針對專業用途的
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 64.31.11.7 (日本)
※ 文章網址: https://webptt.cc/bbs/Stock/M.1765504737.A.BBA.html
大大說得真好 ultra會員太貴了
不過企業跟研究用戶應該願意付錢吧?
不知道之後統計出來美國企業的採用率會不會改變
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:08:26
根據紐約時報十一月底的報導
OPEN AI十月的時候公司內部就發布橙色代碼警報了
(我沒寫錯 不是前陣子那個紅色代碼)
================
10月份,負責ChatGPT的特利先生向全體員工發布了一項緊急通知,宣布進入「橙色警報
」狀態。據四位能夠訪問OpenAI Slack的員工透露,特利先生在通知中寫道,OpenAI正面
臨「前所未有的巨大競爭壓力」。他表示,這款更安全的聊天機器人新版本無法與用戶建
立聯繫。
該通知附帶一份備忘錄,其中列出了各項目標。其中一項目標是在年底前將每日活躍用戶
數提高5%。
================
看來他們是真的有在注意用戶動態 而且很敏感
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:15:25
兩者都很重要 但是應該會把重點放在企業用戶?
11/11華爾街日報報導評估 Claude的公司Anthropic會比OPEN AI較早開獲利
分析的原因之一是因為Anthropic重視企業用戶 而且API高額收費
所以OPEN AI才會發布紅色代碼警戒?不知道市場會怎麼看GPT5.2的表現
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:21:12
你這問題讚 ARC-AGI-1就是因為有公開題庫可以背答案
所以他們才要開發ARC-AGI-2 每一個正式測驗的題目都是新出的
我記得官網好像有在徵求願意幫忙設計題目的人
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:24:17
聽說現在是用強AI或教師AI設計ARC-AGI-2的題目給模型鍛鍊
沒有考古題 所以高階模型自己教自家模型怎麼模擬臨機應變的推理方式
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:27:34
模型知識常識(晶體智力)很強大
常看到一些網友嘲笑LLM是笨蛋 那些人是拿一些人類靠計算機或筆算的方式去考AI
但忽略了AI沒有眼睛 ARC-AGI-2就是在鍛鍊模擬的視覺推理能力
這項如果超過大多數人可能那些笑LLM是笨蛋的再也笑不出來
比喻來說這就好像一個人流體智力到達普通程度 晶體智力卻破表耶 超可怕
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:30:27
感謝提醒
我沒貼錯但貼成沒展開的
那張GPT5.2 Pro (High)右邊的白色三角型是Gemini 3.0 Pro(Refine)
https://i.imgur.com/N6V3Kkv.png
右下方綠色三角形是Gemini 3.0 Pro Deep Think
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:59:23
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 11:00:21
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 11:18:44
https://arcprize.org/arc-agi/2/
頁面下方有三種測驗 分別點TRY THIS TASK可以玩
模型沒有眼睛 所以他們是這樣推的
例如:
(1,1) black (1,2) red (1,3) blue....
把20X20的範例題三題讀取分別的前後變化 找出規則
然後看施測考題 模擬推理出變化後是怎樣的
這全程沒有眼睛可以看 只能靠文字推 很容易出錯 錯一格就是全錯
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 11:45:04
拍拍 我覺得這些題目需要非~~~常細心又認真又花時間
問題就是很容易因為粗心出錯 錯一格就就是錯 沒有商量餘地
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 11:47:41
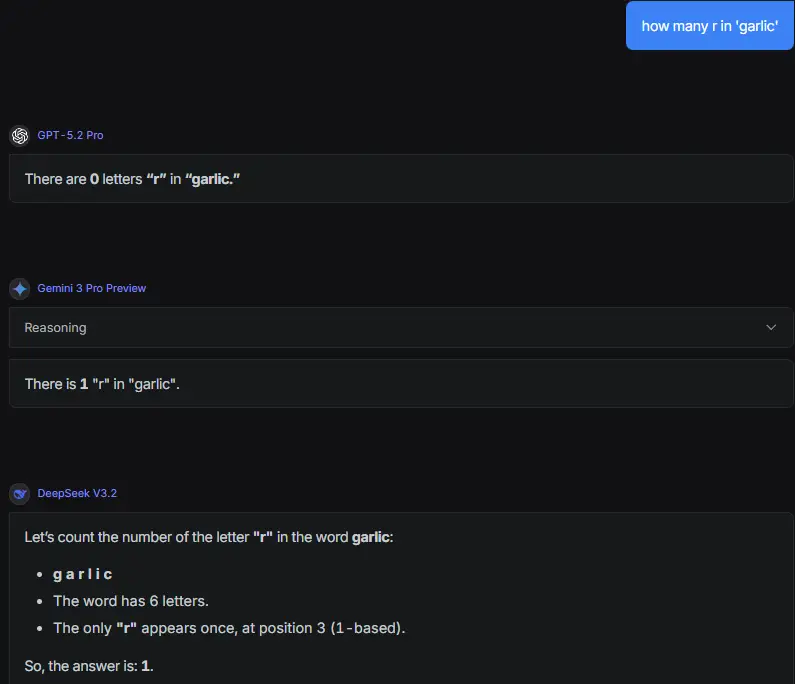 我用不登入頁面問有答對耶
https://i.imgur.com/PX4oZ1F.png
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 12:16:02
感謝分享 原來是5.2才有的現象
GPT5.1的說明: https://i.imgur.com/WhAIS77.png
意思好像是說因為太聰明所以分類器容易疏忽而誤判 分配給錯誤的模型導致答錯
如果是故意選Pro回答那個問題 我覺得可能是故意要看高階推理模型出糗
Gemini 3.0 pro對GPT5.2 Pro出錯的說明:
網友特地選 Pro,就是因為知道 Pro 是經過**「特化訓練(Specialized)」的。而在機
器學習中,越是特化的模型,通常在非專長領域的表現就越容易出現「災難性遺忘」**。
====
Pro 本身的權重,是為了「專業語義工作」優化的(根據 PDF 第 1 頁的定位)。為了在
專業任務上表現穩定(低變異),它犧牲了對字面細節的敏感度(高偏差)。
所以當 Pro 接到任務時,受限於它自身的權重設定(Weights),它看不見字母,只能
用猜的,結果猜錯。
====
如果一開始就選Auto讓分類器自動選派 那還轉給Pro回答就真的很尷尬
如果是故意不用Auto 選用Pro回答這個問題 這算是在找碴
因為權重不一樣 不能說Pro答不出來就代表"新模型GPT5.2連這題都不會"
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 12:17:21
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 13:40:31
我用不登入頁面問有答對耶
https://i.imgur.com/PX4oZ1F.png
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 12:16:02
感謝分享 原來是5.2才有的現象
GPT5.1的說明: https://i.imgur.com/WhAIS77.png
意思好像是說因為太聰明所以分類器容易疏忽而誤判 分配給錯誤的模型導致答錯
如果是故意選Pro回答那個問題 我覺得可能是故意要看高階推理模型出糗
Gemini 3.0 pro對GPT5.2 Pro出錯的說明:
網友特地選 Pro,就是因為知道 Pro 是經過**「特化訓練(Specialized)」的。而在機
器學習中,越是特化的模型,通常在非專長領域的表現就越容易出現「災難性遺忘」**。
====
Pro 本身的權重,是為了「專業語義工作」優化的(根據 PDF 第 1 頁的定位)。為了在
專業任務上表現穩定(低變異),它犧牲了對字面細節的敏感度(高偏差)。
所以當 Pro 接到任務時,受限於它自身的權重設定(Weights),它看不見字母,只能
用猜的,結果猜錯。
====
如果一開始就選Auto讓分類器自動選派 那還轉給Pro回答就真的很尷尬
如果是故意不用Auto 選用Pro回答這個問題 這算是在找碴
因為權重不一樣 不能說Pro答不出來就代表"新模型GPT5.2連這題都不會"
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 12:17:21
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 13:40:31